【產業前線】地表最強交換晶片來襲!Broadcom Tomahawk 6 的三大技術亮點與市場影響
TH6重磅登場,強勢挑戰NVLink Scale-Up市場!

嗨,各位在科技業奮鬥的夥伴們,大家好!
上週的科技圈,特別是網通領域,迎來了一顆重磅炸彈:Broadcom 總算是正式發布了他們最新的交換器晶片 Tomahawk 6。
相信在網通產業第一線的朋友們,可能早就耳聞這顆晶片的風聲,甚至已經悄悄地在進行相關的設計開發了。雖然聽說 Broadcom 的 Sample 還沒完全到位,但台灣的幾家網通大廠早已磨刀霍霍,準備迎接這個新世代的來臨。
Tomahawk 6 不僅僅是一次常規的升級,它更像是一次對未來 AI 基礎設施的宣言。今天,就讓我為大家拆解這顆晶片的幾個關鍵亮點,以及它可能帶來的市場變局。

Tomahawk 6 亮點速覽:數字背後的意義
我們先快速看一下官方公布的驚人規格:
製程工藝: 台積電(TSMC)的 3nm 製程,這代表了頂尖的效能與功耗表現。
晶片版本: 提供兩種型號,滿足不同應用場景:
TH6C: 512 Lanes x 200G/LaneTH6P: 1,024 Lanes x 100G/Lane
總頻寬: 高達 102.4Tbps,正式成為目前世界上單晶片頻寬最高的交換器晶片。
業界最強224G SerDes,與NVLink-C2C相同。
連接能力: 同時支援光纖(Optics)與銅纜(Copper)連接,提供設計彈性。
能夠在部署10 萬個以上 GPU 的大型 AI 叢集時,將所需的網路層數從三層減少到兩層。這可以有效減少延遲與電力消耗!
可以設計成CPO的樣子,不過Broadcom其實有TH6的CPO版本,未來會推出
技術核心:224G SerDes 的挑戰與意義
對我們在訊號完整性耕耘的人來說,最值得關注的無疑是它採用了 224G SerDes 技術。
這代表著單一通道的傳輸速率高達 224 Gbps。有趣的是,這個規格與 NVIDIA 用於連接自家 GPU 的 NVLink-C2C 技術相同,這背後透露的訊息是:整個產業鏈正在向 224G 的生態系靠攏。
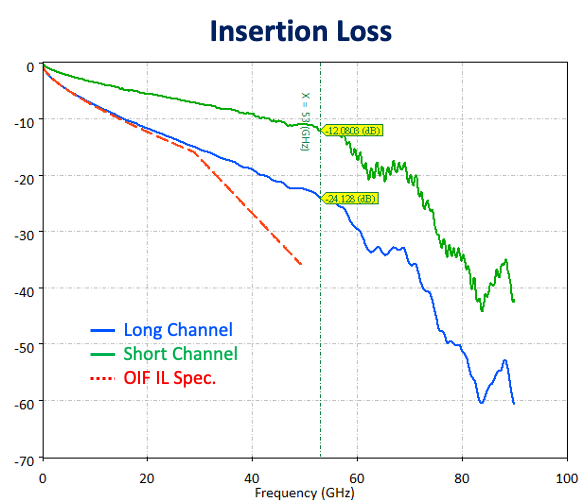
224G SerDes 沿用了上一代112G的 PAM4(四階脈衝幅度調變)訊號,Nyquist frequency從26.56GHz來到53.125GHz,對 PCB 材料選用、Layout佈線技巧、連接器選擇以及晶片等化器(Equalizer)的設計都提出了前所未有的挑戰。如何在高達 112 Gbaud 的速率下,確保訊號的眼圖張開、誤碼率(BER)達標,將是所有硬體設計者接下來幾年的核心課題。
Insertion Loss已經要看到53GHz,損耗的控制將會越來越嚴峻:
👉 點擊閱讀完整文章:800G → 1.6T:PCB CCL 材料如何影響訊號完整性與市場走向?
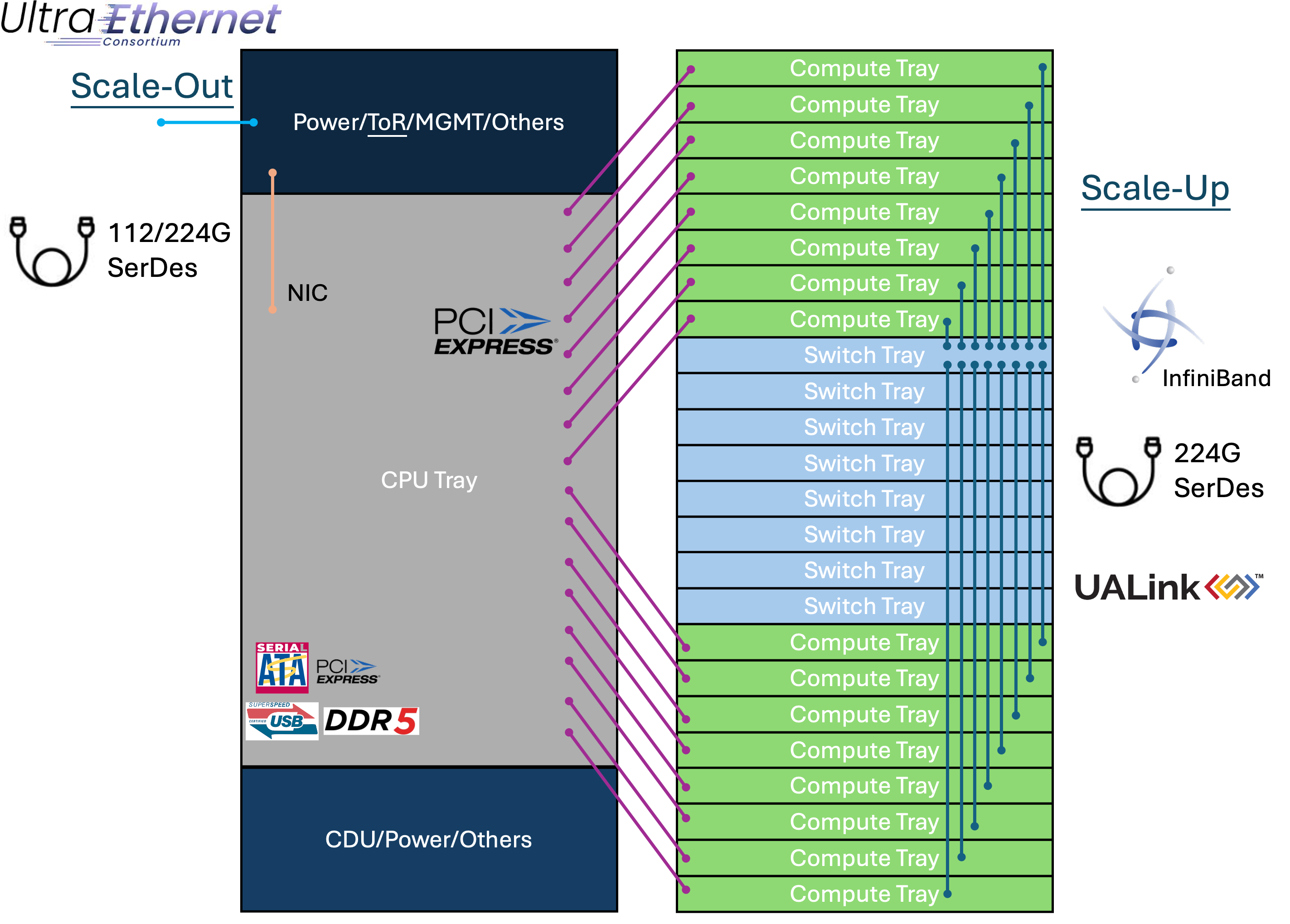
劍指Scale-Up,non-NV陣營當前最佳的Solution
AI 需要”規模化平行計算”,同時間越多的運算核心一起工作是必要的。因此怎麼將所有的晶片連起來,讓GPU/ASIC去擴展(Scalability),進而變成一台”超級 AI 計算機”,就是關鍵中的關鍵!
而這一切的擴展核心,就是高速網路。透過這些網路技術,AI 訓練時可以快速傳遞數據,確保 GPU 之間的梯度更新(Gradient Exchange) 和 模型同步(Model Synchronization) 不會成為瓶頸,讓 AI 訓練更有效率。

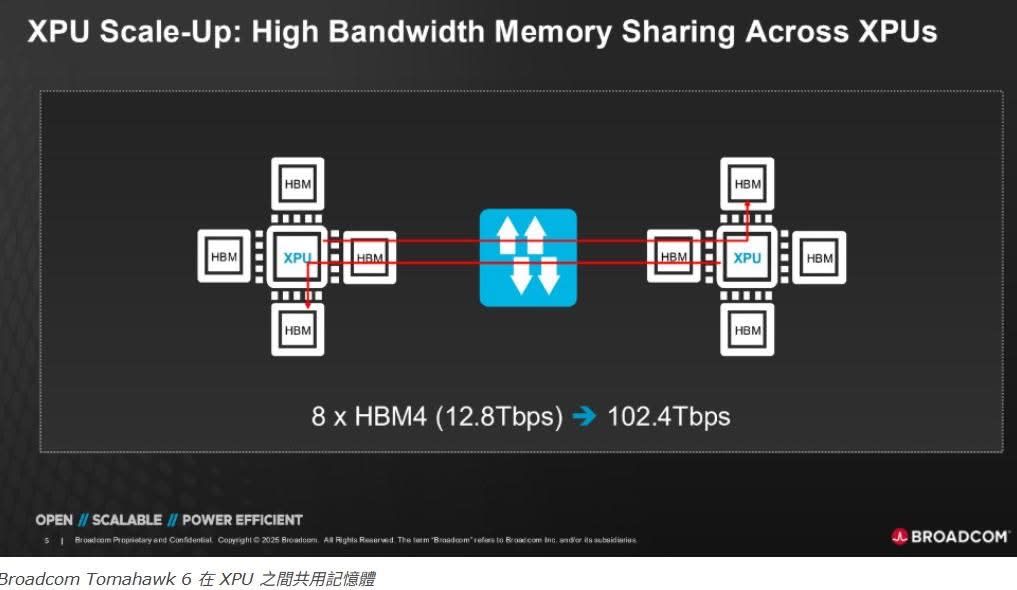

目前市面上最強的Scale-Up技術當指nVIDIA的NVLink-C2C莫屬,non-NV陣營的技術例如Google ICI、AWS NeuronLink、AMD Infinity Fabric等等,其速度與整體頻寬都無法與之相比。但是TH6的出現讓市場有所改變,巨大的網路胃納能力,讓AMD、OpenAI下一世代的產品都將出現 TH6 的蹤影!
👉 點擊閱讀完整文章:AI Rack架構高速互連的挑戰:損耗設計與訊號完整性的設計框架
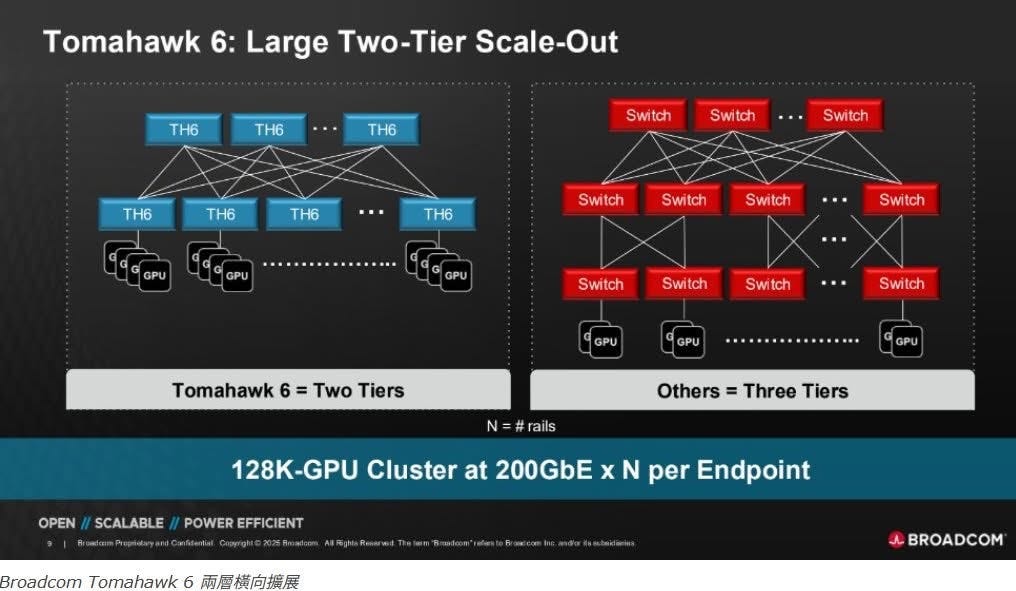
為 AI 叢集而生:從三層到兩層網路的革命
過去,要建構一個擁有數萬、甚至十萬個 GPU 的超大規模 AI 運算叢集,通常需要三層(3-Tier)的交換器網路架構(Leaf-Spine-Core)。這種架構不僅複雜,層層堆疊下也帶來了更高的延遲(Latency)與電力消耗。
Tomahawk 6 的 102.4Tbps 超高頻寬,帶來一個革命性的改變:它能夠將部署超過 10 萬個 GPU 的大型 AI 叢集所需的網路層數,從三層壓縮到兩層(2-Tier)。
這意味著:
延遲更低: 數據傳輸的路徑更短,GPU 之間的通訊效率更高。
功耗更少: 減少了整層的核心交換器,直接降低了巨大的電力與散熱成本。
架構更簡潔: 簡化了網路拓撲,降低了管理與維護的複雜度。

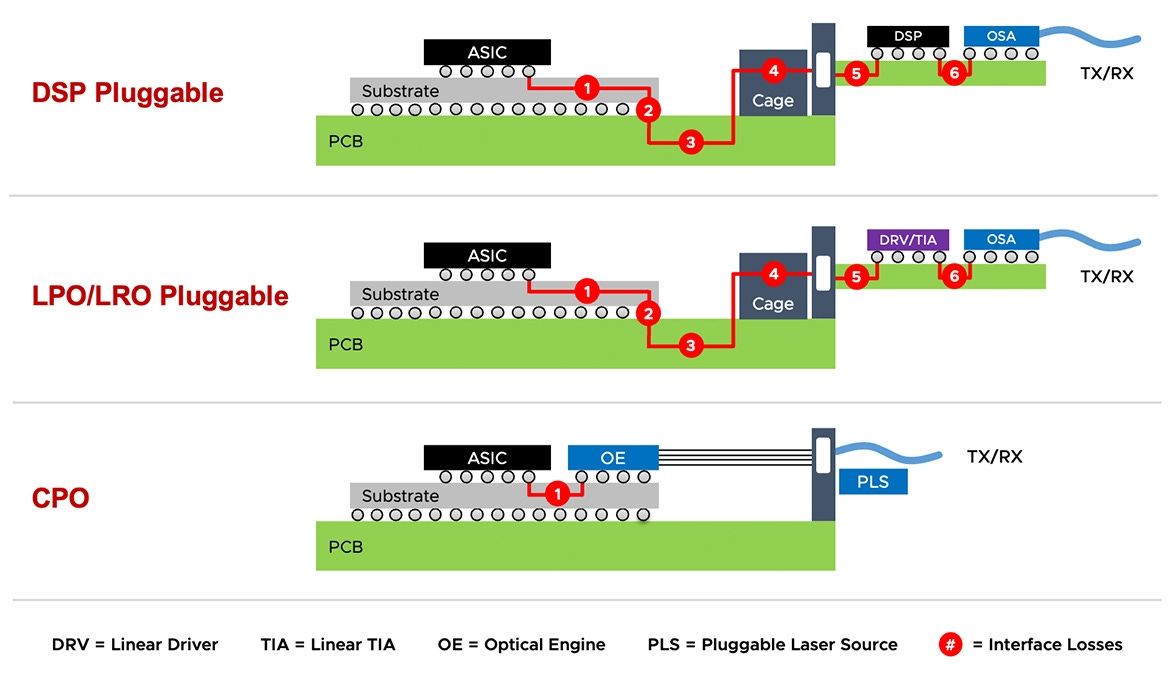
CPO - Co-Packaged Optics
此外,Broadcom 也提到 TH6 可以設計成 CPO 的形式,將OE Engine與交換器晶片封裝在一起,進一步縮短電訊號路徑,實現更低的功耗。我們收到的消息,Broadcom年底也將會推出原生的 Tomahawk 6 CPO 版本,其規格是否跟nVIDIA今年GTC推出的CPO switch有所差別?值得期待。
市場觀察:Ethernet 的野望與 UALink 的挑戰
Broadcom 在發布會上傳達了一個清晰的觀點:未來,Ethernet 的使用率將會超越 InfiniBand。
這是一個非常大膽的預測。長久以來,InfiniBand 以其超低延遲的特性,在高效能運算(HPC)與 AI 領域佔據主導地位。Broadcom 的信心來自於,如果 Ethernet 技術能夠在 Scale-up(向上擴展)的過程中,同樣保證低延遲,並且能支援極大規模的叢集,那麼憑藉其開放、普及的生態系優勢,確實非常有潛力主導市場。
而 Ethernet 在 AI 領域的另一個潛在對手,正是由 Intel、AMD、Microsoft、Meta 等巨頭組成的 UALink(Ultra Accelerator Link)聯盟。
目前 UALink 聯盟還在早期發展階段,標準尚未完全確立。如果 Ethernet 能在此刻憑藉 Tomahawk 6 這樣的武器,快速解決大規模部署下的效能與延遲難題,建立起穩固的市場地位,那麼 UALink 未來的推廣之路恐怕會遇到不小的阻礙。
總結來說,Tomahawk 6 的問世,不僅是硬體規格的競賽,更是乙太網路(Ethernet)陣營在 AI 時代吹響的進攻號角。